Note
Go to the end to download the full example code.
Clustering learning sessions by action patterns#
Scenario: Building on Exploring learner activity sequences, you want to group sessions with similar action sequences together to identify recurring learning strategies. This is the second tutorial in the MOOC series.
Concepts covered:
Rebuild the session pool with
build_states()(self-contained)Compute edit distances with
HammingEntityMetric+EditSequenceMetric(Optimal Matching)Cluster with
HierarchicalClustererInspect cluster membership via
clustersVisualise per-cluster state distributions with a faceted plot
Imports#
import pandas as pd
import polars as pl
from tanat import build_states
from tanat.clustering import HierarchicalClusterer
from tanat.criterion import LengthCriterion
from tanat.dataset import access
from tanat.metric import EditSequenceMetric, HammingEntityMetric
from tanat.visualization import SequenceVisualizer
Rebuild the filtered session pool#
Self-contained rebuild (see Exploring learner activity sequences for details).
INACTIVITY = pd.Timedelta("2h")
df = access("mooc_events")
df["timecreated"] = pd.to_datetime(df["timecreated"])
df = df.sort_values(["user", "timecreated"])
df["session"] = (
(df["user"] != df["user"].shift()) | (df["timecreated"].diff() > INACTIVITY)
).cumsum()
sessions = df[["user", "session"]].drop_duplicates()
df["position"] = df.groupby("session").cumcount()
pool = build_states(
df[["session", "position", "Action"]],
id_column="session",
start_column="position",
static_data=sessions,
store_name="mooc_sessions_store",
)
# ``pl.Categorical`` enables consistent colour-coding across visualisations
# and is required by the metric module.
pool.cast_features({"Action": pl.Categorical}, is_static=False)
ids_keep = pool.which(LengthCriterion(ge=2, le=40))
pool_filtered = pool.subset(ids_keep)
┌─ State SequenceStore
│
│ Step 1/4: Sorting & preparing data
│
│ Step 2/4: Building sequence index
│
│ Step 3/4: Writing entity, time index & static features
│
│ Step 4/4: Computing & writing metadata
│
└─ Done (5,700 sequences · 95,626 entities · 0.02s)
[which] LengthCriterion → 5,150 / 5,700 IDs (90.4%)
print(pool_filtered)
┌────────────────────────────────────────────────┐
│ StateSequencePool Summary │
└────────────────────────────────────────────────┘
Overview
─────────────────────────
Sequences 5,150
Store /home/runner/.tanat_workspace/building_pools_tutorial/mooc_sessions_store
id_column session
Time Index
─────────────────────────
Type Int64 (Timestep) [0 → 39]
Columns ['position', 'end']
t0 position=0, anchor=start
Entity Features (1)
─────────────────────────
• Action Categorical (12 categories)
Static Features (1)
─────────────────────────
• user String [len 9 → 9]
Step 1: Define the sequence metric#
We use Optimal Matching (edit distance), the standard metric for sequence analysis in the social sciences.
HammingEntityMetric compares two actions at the
same position: distance 0 if they share the same type, 1 otherwise.
EditSequenceMetric extends this to full sequences
by counting insertions, deletions, and substitutions.
Tip
You can provide a custom substitution cost matrix to
HammingEntityMetric to reflect domain knowledge
about action similarity (e.g. “Course_view” is closer to “Group_work”
than to “Feedback”). See the API reference for details.
entity_metric = HammingEntityMetric(entity_feature="Action")
sequence_metric = EditSequenceMetric(
entity_metric=entity_metric,
indel_cost=1.0,
)
Step 2: Cluster sessions#
We group sessions into 5 clusters using complete-linkage hierarchical
clustering. After fit(),
the cluster label is automatically added as a static feature under
session_cluster.
clusterer = HierarchicalClusterer(
metric=sequence_metric,
n_clusters=5,
linkage="complete",
cluster_column="session_cluster",
)
clusterer.fit(pool_filtered)
┌─ HierarchicalClusterer
│
│ Step 1/2: Computing distance matrix
│
│ ┌─ EditSequenceMetric
│ │
│ │ Chunks: 0%| | 0/1 [00:00<?, ?it/s]
│ │ Chunks: 100%|██████████| 1/1 [00:03<00:00, 3.28s/it]
│ │ Chunks: 100%|██████████| 1/1 [00:03<00:00, 3.28s/it]
│ │
│ └─ Done (5150 sequences · 3.34s)
│
│ Step 2/2: Clustering (HierarchicalClusterer)
│
└─ Done (5150 items, 5 clusters · 3.74s)
HierarchicalClusterer(clusters=5)
Step 3: Inspect cluster membership#
clusters exposes the fitted
Cluster objects directly.
for cluster in clusterer.clusters:
print(cluster)
Cluster(id=0, size=159)
Cluster(id=1, size=161)
Cluster(id=2, size=38)
Cluster(id=3, size=4523)
Cluster(id=4, size=269)
Cluster labels are also stored as a static feature for downstream use.
pool_filtered.static_data().head()
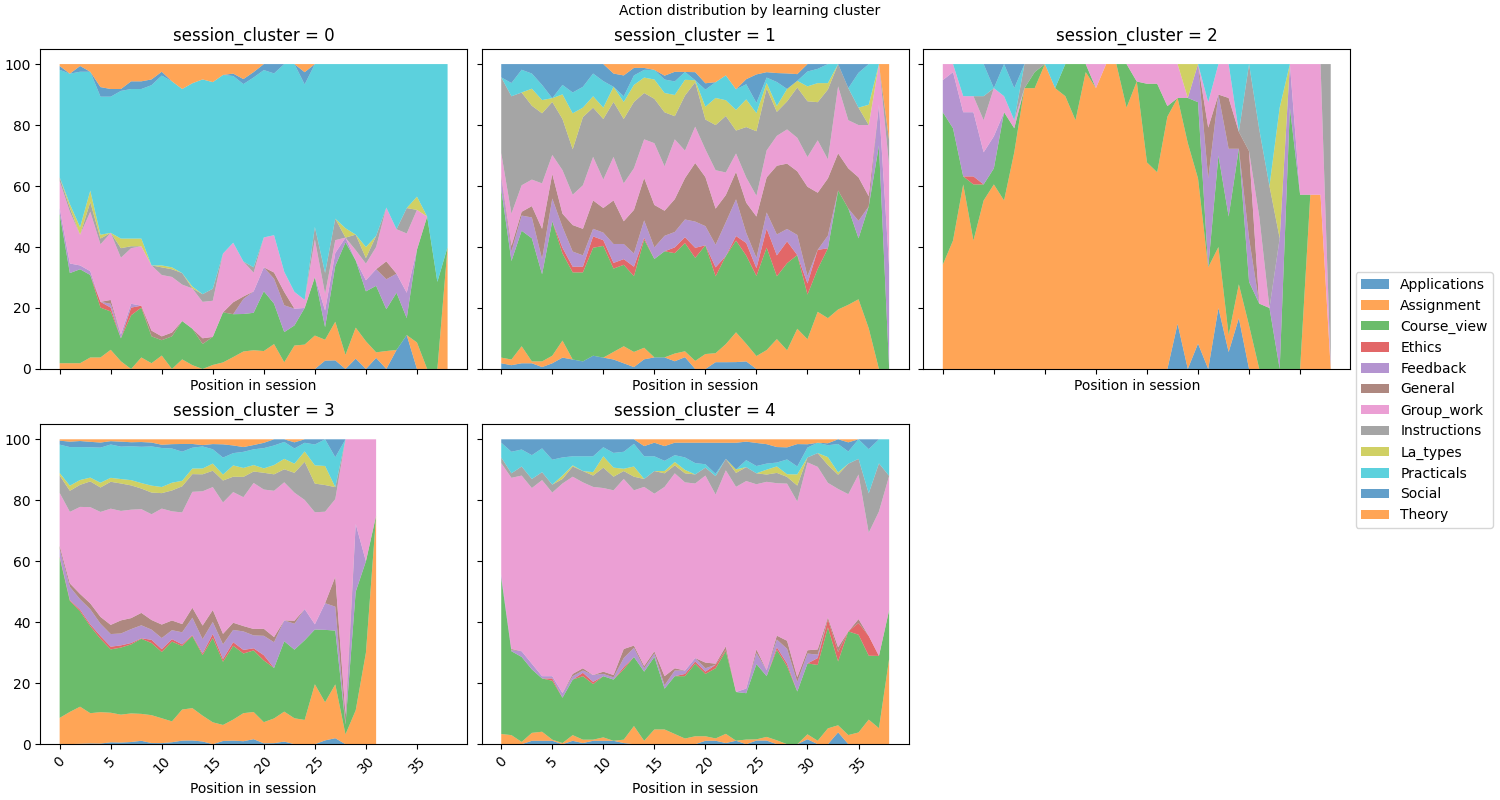
Step 4: Faceted distribution per cluster#
Each panel shows how action proportions evolve across positions for one cluster. Structural differences between clusters reveal distinct learning strategies.
# fmt: off
SequenceVisualizer.distribution(bin_size=1) \
.title("Action distribution by learning cluster") \
.x_axis(label="Position in session") \
.facet(by="session_cluster", is_static=True, cols=3, share_y=True) \
.draw(pool_filtered, entity_feature="Action") \
.show()
# fmt: on
/home/runner/work/TanaT/TanaT/src/tanat/visualization/sequence/base/builder.py:280: UserWarning: 5150 row(s) have a null time index (__END__) and will be excluded from the visualisation.
return self._draw_faceted(
Total running time of the script: (0 minutes 4.957 seconds)